Nous avons vu dans l’ article précédent comment les chercheurs d’ Anthropic ont réussi à modifier un de leurs modèles de langage pour faire apparaître des concepts interprétables au sein des différentes couches du modèle.
Ces recherches, qui remontent à 2024, constituent une première étape. Mais les chercheurs d’ Anthropic sont allés plus loin et ont cherché à comprendre comment ces concepts se combinent dans un modèle pour échafauder une réponse plausible à la demande de l’ utilisateur.
C’ est ce que je vais tenter de vous expliquer dans cet article, et comme vous le verrez, cela apporte pas mal d’ enseignements très intéressants sur le fonctionnement intime des modèles.
Comment tracer les pensées du modèle ?
Nous avons vu dans l’ article précédent comment les chercheurs avaient réussi à adjoindre une sous-couche « interprétable » à chaque couche du modèle, ce qui permettait d’ identifier et de localiser un ensemble de concepts. Mais ce mécanisme ne permettait pas encore de comprendre comment ces concepts s’ articulent en une réflexion cohérente.
Pour pouvoir tracer les pensées du modèle, les chercheurs ont créé un modèle de substitution plus riche que celui présenté dans l’ article précédent:
- chaque couche du modèle original est remplacée par une couche interprétable équivalente, appelée couche de transcodage;
- chaque couche de transcodage agit non seulement sur la prochaine couche du modèle mais aussi les couches suivantes. Ceci permet à une caractéristique interprétable située en amont du modèle d’ agir directement sur une autre caractéristique interprétable située n’ importe où en aval.
Ceci mène au modèle de substitution présenté dans la figure 1.

Une fois que ce modèle de remplacement a été correctement entraîné, on va pouvoir lui soumettre un texte d’ entrée et voir quelles sont les caractéristiques interprétables qui sont activées par la question, mais aussi comment ces caractéristiques s’ influencent mutuellement pour aboutir à la formation de la réponse.
En fait le « truc » est toujours le même : on remplace un modèle par un autre qui fait la même chose mais dans lequel on peut mesurer ce qui nous intéresse. Parce que les informaticiens ont un grand avantage sur les biologistes : tous les calculs intermédiaires sont accessibles et tout est mesurable !
Le résultat de ces mesures se présente sous la forme de graphes d’attribution, une représentation graphique des étapes de calcul utilisées par le modèle pour déterminer le texte de sortie pour un texte d’ entrée particulier.
Voici un exemple de graphe d’ attribution simple pour vous donner une idée de ce que cela signifie :

Voyons maintenant quelques découvertes intéressantes que les chercheurs ont faites en analysant les graphes d’ attribution générés pour des textes d’ entrée judicieusement choisis…
Découverte 1 : les modèles ne dévoilent pas toujours leurs pensées
C’ est la première question à se poser : demandez au modèle d’ expliquer chaque étape de son raisonnement (chain of thought prompting). L’ explication fournie correspond-elle systématiquement au raisonnement intérieur du modèle?
Parce que si c’ est le cas, pas besoin de faire toutes ces recherches, il suffit de demander au modèle d’ expliciter son raisonnement. Malheureusement, ce n’ est pas ce que les chercheurs ont découvert.
Prenons un exemple simple de calcul mental. Les chercheurs ont demandé au modèle combien font 36+59. Ils ont découvert que le modèle utilise « en interne » un double chaîne de raisonnement, la première cherchant une réponse approximative et la seconde se limitant à calculer le chiffre des unités; les deux sont ensuite combinés pour estimer une réponse. A noter que c’ est assez proche de ce que nous faisons intuitivement en calcul mental.
Voici le graphe d’ attribution correspondant :
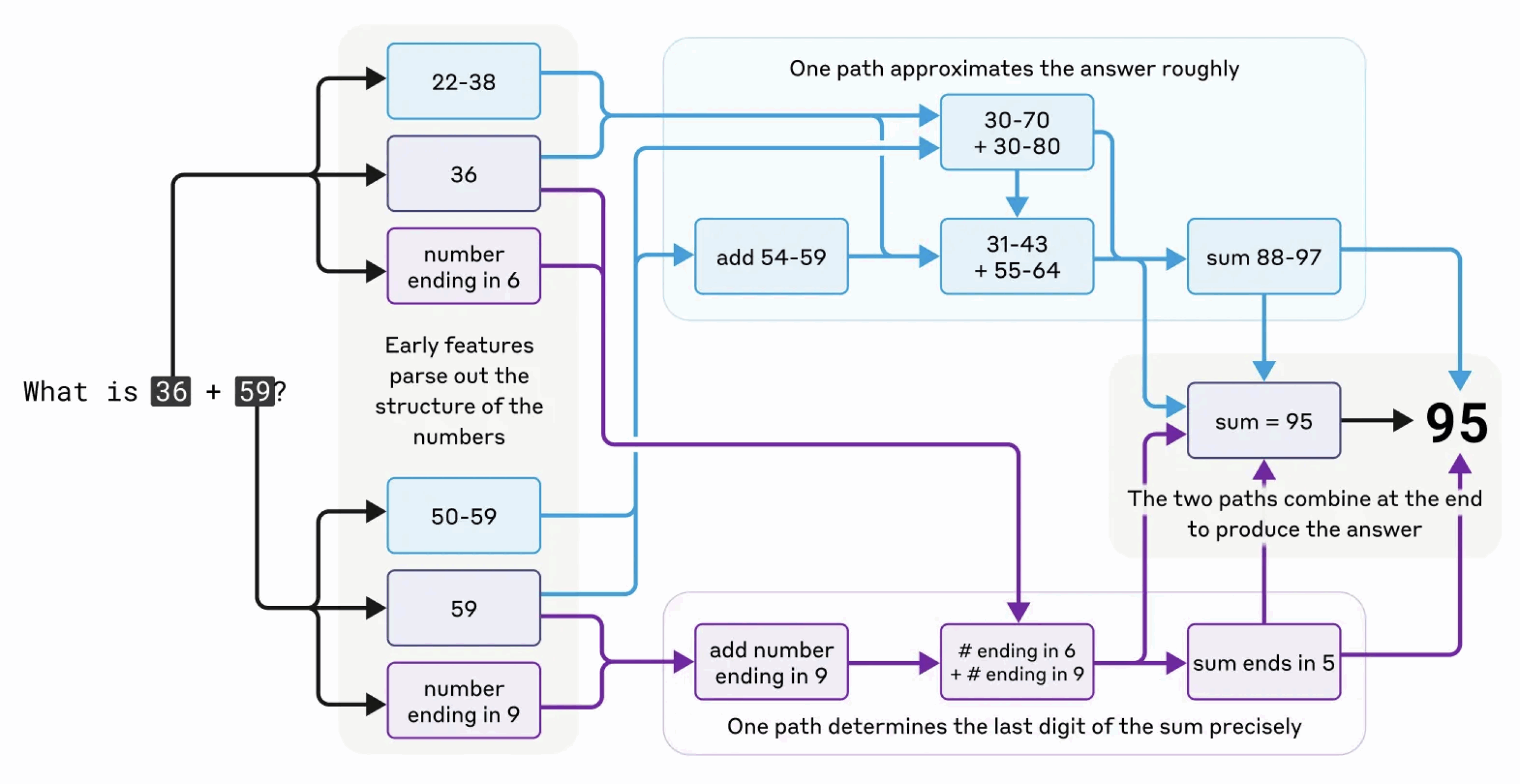
Mais quand on demande au modèle d’ expliquer son raisonnement, il explique l’ algorithme standard d’addition écrite avec le report des unités sur les dizaines. Ce qui est un tout autre mécanisme !

Plus généralement, les chercheurs ont remarqué que le modèle décrit son raisonnement correctement dans certains cas, mais ce n’ est pas systématique.
Par exemple, lorsqu’ on lui demande de calculer le cosinus d’un grand nombre qu’ il ne peut pas calculer facilement, le modèle se livre parfois à ce que les chercheurs appellent du bullshitting (!), c’est-à-dire qu’ il donne une réponse, n’ importe laquelle, sans se soucier de savoir si elle est vraie ou fausse. Même s’ il prétend avoir effectué un calcul, les techniques d’ interprétabilité ne révèlent aucune preuve de l’ existence de ce calcul !
Autre cas intéressant, lorsqu’ on lui donne un calcul ainsi que sa réponse et on lui demande d’ expiquer comment trouver le résultat, le modèle travaille parfois à rebours, trouvant des étapes intermédiaires qui mèneraient à cette cible, faisant ainsi preuve d’ une forme de raisonnement motivé. D’ autant plus qu’ il n’ hésite pas à faire aussi cela lorsque la réponse qu’ on lui donne est fausse !
Bref, on ne peut pas considérer les explications et justifications du modèle comme transparentes et une analyse « intrusive » est nécessaire pour comprendre ce qui se passe réellement dans sa « tête ». C’ est bien dommage mais c’ est comme ça.
Découverte 2 : le modèle possède un seul modèle cognitif multilingue
Ceci est, pour moi, remarquable : le modèle semble posséder un espace conceptuel unique qui est partagé entre les différentes langues, ce qui suggère qu’il possède une sorte de « langage de pensée » universel.
En effet, comme l’ entraînement des modèles se fait sur un ensemble de textes en grande majorité individuellement unilingues, on pourrait imaginer que ces modèles contiennent en leur sein une série de mini-modèles conceptuels indépendants, chaque langue créant sa propre réalité intérieure au fil de l’ entraînement.
Au contraire, les chercheurs d’ Anthropic ont montré qu’ il n’ existe pas de «modèle français» ni de «modèle chinois» fonctionnant en parallèle et répondant aux demandes dans leur propre langue.
Ils ont demandé au modèle le « contraire de petit » dans différentes langues, les mêmes caractéristiques fondamentales des concepts de petitesse et d’ opposition s’ activent pour déclencher un concept de grandeur, qui est finalement traduit dans la langue de la question.

D’ un point de vue pratique, cela suggère que les modèles peuvent apprendre quelque chose dans une langue et appliquer ces connaissances lorsqu’ ils conversent dans une autre langue, ce qui est tout à fait positif et très important à comprendre.
Découverte 3 : le modèle planifie sa réponse plusieurs mots à l’ avance
L’ algorithme de base des modèles de langage repose sur une prédiction mot à mot. Mais le modèle planifie-t’ il plus loin que le prochain mot ? A-t’ il une idée « derrière la tête » quand il fait sa prédiction ?
Un bon cas pour tester ceci est la rédaction d’ un poème. En effet, pour écrire un poème, il faut satisfaire à deux contraintes en même temps : les vers doivent rimer et ils doivent avoir un sens. Il y a deux façons d’ imaginer comment un modèle y parvient :
- l’ improvisation pure – le modèle pourrait écrire le début de chaque ligne sans se soucier de la nécessité de rimer à la fin. Puis, au dernier mot de chaque ligne, il choisirait un mot qui (1) a un sens compte tenu de la ligne qu’il vient d’écrire et (2) correspond au schéma de rimes;
- la planification – le modèle peut également adopter une stratégie plus sophistiquée. Au début de chaque ligne, il pourrait imaginer le mot qu’ il prévoit d’ utiliser à la fin, en tenant compte du schéma de rimes et du contenu des lignes précédentes. Il pourrait ensuite utiliser ce « mot prévu » pour rédiger la ligne suivante, de manière à ce que le mot prévu s’ insère naturellement à la fin de la ligne.
Lequel des deux modèles est correct ? Vu l’ algorithme des modèles de langage, on pourrait pencher pour la première hypothèse. C’ était d’ ailleurs ce que pensaient des chercheurs au début de leurs recherches. Et pourtant, ils ont trouvé des éléments suggérant clairement que le modèle fait de la planification plusieurs mots à l’ avance…
Comme on peut le voir sur la figure 6, le modèle planifie à l’ avance plusieurs possibilités pour le mot final de la ligne, et planifie ensuite le reste de la ligne « à l’envers » pour que cette dernière soit cohérente.

Les chercheurs ont également modifié les concepts en cours d’ élaboration de la rime. Le modèle prévoyait de terminer sa ligne par « rabbit » mais si l’ on annule ce concept en cours de route voire le remplace par un autre, le modèle change de rime.

Ceci montre que les modèles préparent leurs réponses plusieurs mots à l’ avance, et sont non seulement capbles de planifier vers l’ avant mais aussi vers l’ arrière (rétro-planning) quand c’ est nécessaire. Les modèles sont aussi capables de planifications multiples en parallèle, et il est possible d’ intervenir directement sur ces plans en cours de route en modifiant les concepts sous-jacents.
Conclusion
Ces recherches lèvent un coin du voile sur ce qui se passe réellement au sein des modèles de langage. Il me semble clair que ces recherches ne sont qu’ à leurs débuts et que beaucoup de choses sont encore à découvrir dans le domaine de l’ interprétabilité.
Si vous voulez en savoir plus sur ce sujet, je ne puis que vous suggérer de lire directement l’ article On the Biology of a Large Language Model que je cite ci-dessous en référence. Les chercheurs y présentent douze traces de raisonnement différentes apportant chacune son lot d’ enseignements…
Pour ma part, ce qui me fascine le plus, ce sont les analogies évidentes entre la manière dont ces modèles « réfléchissent » et la manière dont nous le faisons…
Sources et références
- Tracing the thoughts of a Large Language Model, par Anthropic Interpretability research team, le 27 mars 2025: https://www.anthropic.com/research/tracing-thoughts-language-model
- Circuit Tracing: Revealing Computational Graphs in Language Models, par Anthropic Interpretability research team, le 27 mars 2025 : https://transformer-circuits.pub/2025/attribution-graphs/methods.html
- On the Biology of a Large Language Model, , par Anthropic Interpretability research team, le 27 mars 2025: https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- What’s going on inside Claude’s mind ?, par Nikhil Anand pour Medium, le 23 mai 2025 : https://medium.com/ai-advances/whats-going-on-inside-claude-s-mind-bfb8bb9cf6a1






