Le 24 novembre 2025, le président des États-Unis signe un décret historique: le lancement officiel de la Mission Genesis, une initiative de grande envergure destinée à fusionner données publiques, super-ordinateurs, laboratoires nationaux et intelligence artificielle.
La mission sera conduite par l’U.S. Department of Energy (DoE), à travers ses 17 laboratoires nationaux, en collaboration avec universités, entreprises technologiques et centres de recherche. Elle s’appuiera sur l’expertise des quelque 40 000 scientifiques, ingénieurs et techniciens du DoE, ainsi que sur celle des acteurs secteur privé.
L’ initiative a pour objectif d’ ouvrir une nouvelle ère d’ innovation et de découvertes accélérées par l’IA, capables de répondre aux défis les plus complexes de notre époque. Elle se concentrera sur des défis majeurs comme la fusion nucléaire, les réacteurs nucléaires avancés, la modernisation du réseau électrique, les nouveaux matériaux, l’ informatique quantique et la mise au point de nouveaux médicaments.
Figure 1 : Pictogramme de la Mission Genesis
Contenu du projet Genesis
L’ idée est de bâtir une plateforme intégrée qui permettra d’ entraîner des modèles IA scientifiques avancés menant à des agents chercheurs autonomes fonctionnant en boucle fermée. Ceux-ci pourront à la fois contenir des modèles génératifs, pour échafauder des hypothèses créatives, mais aussi des modèles prédictifs afin d’ orienter et de valider les intuitions du modèle génératif.
Le processus scientifique décrit dans la feuille de route du DOE relève presque de la science-fiction :
La conception par l’ IA : elle examine les données et émet l’hypothèse suivante : « Si nous mélangeons ces alliages à 4 000 degrés, nous obtenons un supraconducteur. »;
L’ IA définit ensuite un protocole de validation expérimental et l’ envoie à un laboratoire lui aussi robotisé (que le DoE est en train de construire) pour réaliser le mélange et tester ses propriétés;
Le robot renvoie instantanément les résultats. En cas d’échec, l’ IA modifie la formule;
Ce cycle se répète des milliers de fois par jour, 24 heures sur 24, 7 jours sur 7. Pas de sommeil. Pas de demande de subvention.
Le projet se caractérise aussi par des délais ambitieux, qui attestent de son importance pour l’ administration américaine :
60 jours pour identifier 20 défis hautement prioritaires à relever;
90 jours pour répertorier toutes les ressources informatiques à sa disposition;
120 jours pour établir un plan visant à exploiter les données provenant à la fois de sources fédérales et d’autres instituts de recherche;
270 jours pour démontrer que son plan peut permettre de progresser sur au moins l’ un des défis identifiés.
Réflexions
Que l’ on ne s’ y trompe pas, il s’ agit d’ une initiative majeure. Lors d’une conférence de presse, Michael Kratsios, conseiller scientifique du président Trump, a qualifié la mission Genesis de « plus grande mobilisation de ressources scientifiques fédérales depuis le programme Apollo ».
Un des objectifs centraux de cette mission est de doubler la productivité et l’ impact de la recherche et de l’ innovation américaines en l’ espace d’ une décennie en assistant les effectifs scientifiques avec de l’ IA plutôt qu’en les remplaçant. Ce n’est pas rien.
De plus, les laboratoires du Department of Energy disposent des supercalculateurs les plus rapides et d’ une expérience dans la conduite de recherches contrôlées à haut risque, essentielle pour l’ expérimentation dans certains domaines.
Les géants de l’ IA américaine (Google, OpenAI, Anthropic, Nvidia etc..) sont aussi cités comme participants et devraient obtenir l’ accès à des pétaoctets de données expérimentales exclusives qui ont été conservées dans des installations gouvernementales sécurisées pendant des décennies.
Toutes ces données, jusqu’ ici cloisonnées au sein des archives scientifiques du NIH, du DOE, de la NASA, de la NOAA, de la DARPA, de la NSF, du CDC, de la FDA, de l’USDA, du Bureau du recensement et des services de renseignement seront regroupées dans un ensemble unifié.
Ceci ne signifie cependant pas que les géants de la tech sont au centre de cette initiative; ils interviendront plutôt en tant qu’ experts et conseillers, mais bénéficieront de ses retombées.
Les capacités des modèles feront un bond en avant, car ces données contiennent précisément le type d’ informations à haut signal, structurées et à long terme dont les modèles de pointe ont besoin pour leur entraînement.
Imaginez un outil qui, en moins de trois ans, devient une habitude hebdomadaire pour plus de 700 millions d’ utilisateurs, soit environ 10% de la population adulte du monde.
Cet outil, c’ est bien sûr ChatGPT, qui répondait en moyenne à 2,5 millards de questions par jour en juin 2025 (soit environ 29.000 par seconde!). Mais que demandent les utilisateurs ? A quelles fins utilisent-ils des modèles de langage ?
OpenAI et le National Bureau of Economic Research (NBER) ont rédigé la première étude statistique détaillée d’utilisation du modèle de langage le plus populaire : ChatGPT. Ce sont les résultats de cette étude que je voudrais vous présenter dans cet article.
Attention : l’ étude ne porte que sur l’ interface web ChatGPT et ne reprend que les utilisateurs sur les plans « consommateur » (Free, Plus et Pro). Les utilisateurs sur les plans entreprise (Business et Enterprise) ne sont pas repris, ni les accès par API, ce qui a des conséquences pour l’ interprétation des résultats…
1. Profil des utilisateurs et volumes de conversation
Voyons d’ abord le nombre d’ utilisateurs ChatGPT actifs au moins une fois par semaine. Ce nombre passe de 100 millions début 2024 à 400 millions début 2025 pour atteindre en juillet 2025 environ 700 millions d’ utilisateurs soit 10% de la population adulte mondiale; ces chiffres sont cependant un peu surévalués car ils mesurent le nombre de comptes et certains utilisateurs peuvent disposer de plusieurs comptes.
Figure 1 : Nombre de comptes ChatGPT (« Free », »Plus », »Pro ») actifs au moins une fois par semaine (crédit : étude OpenAI/NBER)
Quant au nombre total de messages échangés chaque jour sur ChatGPT, il passe de 451 millions en juin 2024 à environ 2,6 milliards en juin 2025 (en moyennes hebdomadaires) et tout semble indiquer que cette croissance devrait se poursuivre. Pour donner une idée de comparaison, Google a indiqué au mois de mars traiter approximativement 14 milliards de recherches par jour.
Un point intéressant est que la croissance du trafic sur le site de ChatGPT semble provenir essentiellement de l’ arrivée de nouveaux utilisateurs, et non d’ une augmentation de la fréquence d’ utilisation par les utilisateurs plus anciens, qui reste stable.
Quant au profil des utilisateurs, il est clairement orienté vers les jeunes puisque 46% des utilisateurs ayant mentionné leur âge ont entre 18 et 25 ans. Et si 80% des utilisateurs étaient des hommes lors du lancement de ChatGPT fin 2022, la proportion est passée à 52% de femmes aujourd’ hui ce qui est en phase avec la moyenne de la population.
Enfin, une tendance très intéressante est que ChatGPT connaît actuellement une croissance quatre fois supérieure dans les pays à faibles et moyens revenus par rapport aux pays les plus riches. Ceci montre la globalisation rapide de cet outil.
2. Catégories d’ utilisation
L’ étude a analysé de manière détaillée et classé plus d’ un million de conversations provenant de la base globale des utilisateurs de ChatGPT, tout en protégeant l’ anonymité des messages individuels.
Figure 2 : Répartition des conversations par catégorie (crédit : étude OpenAI/NBER)
Les catégories d’ utilisation les plus fréquentes sont :
conseils pratiques (28,3%) : instruction et éducation, explications « comment faire? », conseils de beauté, de fitness ou de soins….
écriture (28,1%) : il est intéressant ici que les demandes de rédaction directe (8%) sont inférieures aux demandes d’ édition et de revue de textes déjà rédigés (10,6%). La traduction de textes compte pour environ 4,5% des conversations;
recherche d’ informations (21,3%) : cette catégorie est en forte croissance, passant de 14% des utilisateurs à 24,4% en un an (le chiffre de 21,3% est une moyenne). Il est intéressant que la tendance des modèles de langage à occasionnellement affabuler ne semble pas rebuter les utilisateurs; il est vrai que les modèles de langage se sont améliorés dans la fourniture de liens vers leurs sources, ce qui permet une vérification de l’ information a posteriori.
Par contre, seuls 1,9% des messages ont trait à des questions relationnelles ou à des réflections personnelles, et 2% à du bavardage et à des salutations(!). Quoi qu’ en disent les médias, un outil comme ChatGPT est utilisé comme un outil et non comme un compagnon ou un confident.
3. L’ utilisation privée avant le travail
Autre point intéressant, les chercheurs ont cherché à distinguer les conversations à caractère professionnel de celles à caractère privé. Et les conclusions sont claires : la proportion des conversations non-professionelles est passée en un an de 53% à 72,2%.
Malgré toutes les déclarations suggérant que les modèles de langage vont révolutionner l’ emploi et le milieu professionnel, une conclusion s’ impose : ChatGPT est principalement un outil utilisé dans la vie privée.
Figure 3 : Proportion de conversations à caractère non-professionnel (crédit : étude OpenAI/NBER)
Ce constat doit être fait avec une réserve : les abonnements « entreprise » ne sont pas repris dans l’ étude et il est probable que leur inclusion augmenterait la part de conversations professionnelles, mais sans toutefois remettre en cause le caractère principalement privé de l’ utilisation.
Les utilisateurs hautement qualifiés et ceux exerçant des professions libérales sont plus susceptibles d’ utiliser ChatGPT dans le cadre de leur travail. Dans le cadre professionnel, les utilisateurs techniques envoient davantage de messages de questionnement et de recherche d’ informations, tandis que les cadres se concentrent sur la rédaction (52 % de leurs messages professionnels).
4. Les absents
L’ étude fait aussi état d’ une utilisation assez faible des capacités de traitement des images offertes par ChatGPT, tant en analyse qu’en génération (environ 6% des requêtes).
De même la programmation est peu présente (4,2% des requêtes), ce qui paraît surprenant. La raison est très probablement l’ exclusion de l’ interface API de l’ étude, alors que les assistants intégrés de programmation type Github Copilot et Cursor recourent systématiquement à l’ accès par l’ API.
5. Remarques finales
Anthropic a publié une étude comparable relative à l’ utilisation de Claude le même jour qu’ OpenAI (le 15 septembre) et les résultats de cette seconde étude sont assez différents !
Le grand avantage de l’ étude d’ Anthropic est qu’ elle couvre aussi les accès API; elle est donc plus complète. Elle est aussi entièrement accessible alors que l’ étude complète d’ OpenAI se trouve sur le site du National Bureau of Economic Research et n’ est pas librement accessible; je confesse que j’ai dû baser cet article sur des sources indirectes….
Je vous présenterai les résultats de l’ étude d’ Anthropic dans le prochain article.
D’ ici là, portez-vous bien et n’ oubliez pas de soumettre toutes vos questions -même les plus insolites- à votre modèle de langage favori.
Nous avons vu dans l’ article précédent comment les chercheurs d’ Anthropic ont réussi à modifier un de leurs modèles de langage pour faire apparaître des concepts interprétables au sein des différentes couches du modèle.
Ces recherches, qui remontent à 2024, constituent une première étape. Mais les chercheurs d’ Anthropic sont allés plus loin et ont cherché à comprendre comment ces concepts se combinent dans un modèle pour échafauder une réponse plausible à la demande de l’ utilisateur.
C’ est ce que je vais tenter de vous expliquer dans cet article, et comme vous le verrez, cela apporte pas mal d’ enseignements très intéressants sur le fonctionnement intime des modèles.
Comment tracer les pensées du modèle ?
Nous avons vu dans l’ article précédent comment les chercheurs avaient réussi à adjoindre une sous-couche « interprétable » à chaque couche du modèle, ce qui permettait d’ identifier et de localiser un ensemble de concepts. Mais ce mécanisme ne permettait pas encore de comprendre comment ces concepts s’ articulent en une réflexion cohérente.
Pour pouvoir tracer les pensées du modèle, les chercheurs ont créé un modèle de substitution plus riche que celui présenté dans l’ article précédent:
chaque couche du modèle original est remplacée par une couche interprétable équivalente, appelée couche de transcodage;
chaque couche de transcodage agit non seulement sur la prochaine couche du modèle mais aussi les couches suivantes. Ceci permet à une caractéristique interprétable située en amont du modèle d’ agir directement sur une autre caractéristique interprétable située n’ importe où en aval.
Ceci mène au modèle de substitution présenté dans la figure 1.
Figure 1 : Du modèle original au modèle de remplacement
Une fois que ce modèle de remplacement a été correctement entraîné, on va pouvoir lui soumettre un texte d’ entrée et voir quelles sont les caractéristiques interprétables qui sont activées par la question, mais aussi comment ces caractéristiques s’ influencent mutuellement pour aboutir à la formation de la réponse.
En fait le « truc » est toujours le même : on remplace un modèle par un autre qui fait la même chose mais dans lequel on peut mesurer ce qui nous intéresse. Parce que les informaticiens ont un grand avantage sur les biologistes : tous les calculs intermédiaires sont accessibles et tout est mesurable !
Le résultat de ces mesures se présente sous la forme de graphes d’attribution, une représentation graphique des étapes de calcul utilisées par le modèle pour déterminer le texte de sortie pour un texte d’ entrée particulier.
Voici un exemple de graphe d’ attribution simple pour vous donner une idée de ce que cela signifie :
Voyons maintenant quelques découvertes intéressantes que les chercheurs ont faites en analysant les graphes d’ attribution générés pour des textes d’ entrée judicieusement choisis…
Découverte 1 : les modèles ne dévoilent pas toujours leurs pensées
C’ est la première question à se poser : demandez au modèle d’ expliquer chaque étape de son raisonnement (chain of thought prompting). L’ explication fournie correspond-elle systématiquement au raisonnement intérieur du modèle?
Parce que si c’ est le cas, pas besoin de faire toutes ces recherches, il suffit de demander au modèle d’ expliciter son raisonnement. Malheureusement, ce n’ est pas ce que les chercheurs ont découvert.
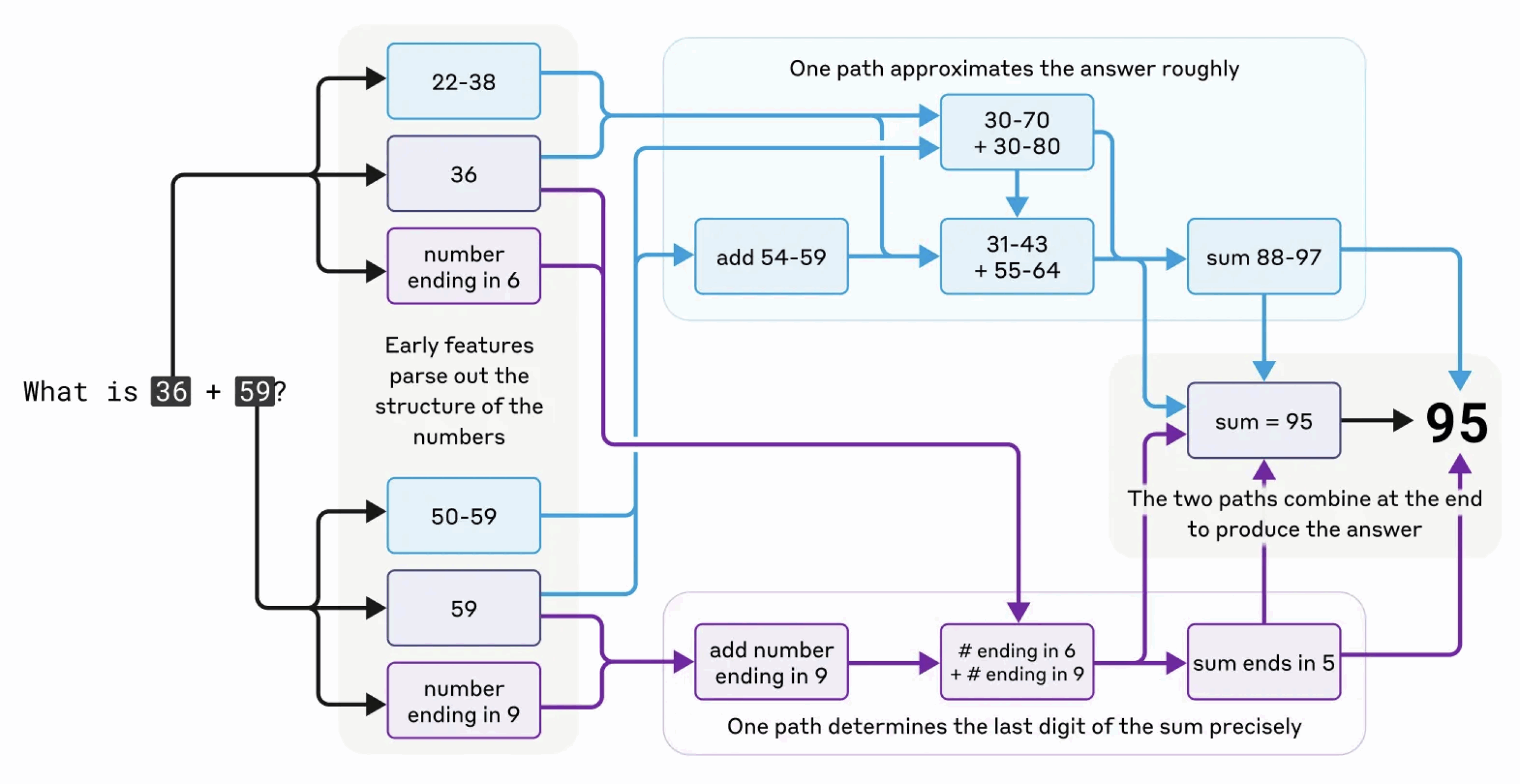
Prenons un exemple simple de calcul mental. Les chercheurs ont demandé au modèle combien font 36+59. Ils ont découvert que le modèle utilise « en interne » un double chaîne de raisonnement, la première cherchant une réponse approximative et la seconde se limitant à calculer le chiffre des unités; les deux sont ensuite combinés pour estimer une réponse. A noter que c’ est assez proche de ce que nous faisons intuitivement en calcul mental.
Voici le graphe d’ attribution correspondant :
Figure 3 : Graphe d’ attribution pour un calcul élémentaire (source : Anthropic)
Mais quand on demande au modèle d’ expliquer son raisonnement, il explique l’ algorithme standard d’addition écrite avec le report des unités sur les dizaines. Ce qui est un tout autre mécanisme !
Figure 4 : Explication fournie par le modèle (source : Anthropic)
Plus généralement, les chercheurs ont remarqué que le modèle décrit son raisonnement correctement dans certains cas, mais ce n’ est pas systématique.
Par exemple, lorsqu’ on lui demande de calculer le cosinus d’un grand nombre qu’ il ne peut pas calculer facilement, le modèle se livre parfois à ce que les chercheurs appellent du bullshitting (!), c’est-à-dire qu’ il donne une réponse, n’ importe laquelle, sans se soucier de savoir si elle est vraie ou fausse. Même s’ il prétend avoir effectué un calcul, les techniques d’ interprétabilité ne révèlent aucune preuve de l’ existence de ce calcul !
Autre cas intéressant, lorsqu’ on lui donne un calcul ainsi que sa réponse et on lui demande d’ expiquer comment trouver le résultat, le modèle travaille parfois à rebours, trouvant des étapes intermédiaires qui mèneraient à cette cible, faisant ainsi preuve d’ une forme de raisonnement motivé. D’ autant plus qu’ il n’ hésite pas à faire aussi cela lorsque la réponse qu’ on lui donne est fausse !
Bref, on ne peut pas considérer les explications et justifications du modèle comme transparentes et une analyse « intrusive » est nécessaire pour comprendre ce qui se passe réellement dans sa « tête ». C’ est bien dommage mais c’ est comme ça.
Découverte 2 : le modèle possède un seul modèle cognitif multilingue
Ceci est, pour moi, remarquable : le modèle semble posséder un espace conceptuel unique qui est partagé entre les différentes langues, ce qui suggère qu’il possède une sorte de « langage de pensée » universel.
En effet, comme l’ entraînement des modèles se fait sur un ensemble de textes en grande majorité individuellement unilingues, on pourrait imaginer que ces modèles contiennent en leur sein une série de mini-modèles conceptuels indépendants, chaque langue créant sa propre réalité intérieure au fil de l’ entraînement.
Au contraire, les chercheurs d’ Anthropic ont montré qu’ il n’ existe pas de «modèle français» ni de «modèle chinois» fonctionnant en parallèle et répondant aux demandes dans leur propre langue.
Ils ont demandé au modèle le « contraire de petit » dans différentes langues, les mêmes caractéristiques fondamentales des concepts de petitesse et d’ opposition s’ activent pour déclencher un concept de grandeur, qui est finalement traduit dans la langue de la question.
Figure 5 : Le modèle conceptuel multilingue (source: Anthropic)
D’ un point de vue pratique, cela suggère que les modèles peuvent apprendre quelque chose dans une langue et appliquer ces connaissances lorsqu’ ils conversent dans une autre langue, ce qui est tout à fait positif et très important à comprendre.
Découverte 3 : le modèle planifie sa réponse plusieurs mots à l’ avance
L’ algorithme de base des modèles de langage repose sur une prédiction mot à mot. Mais le modèle planifie-t’ il plus loin que le prochain mot ? A-t’ il une idée « derrière la tête » quand il fait sa prédiction ?
Un bon cas pour tester ceci est la rédaction d’ un poème. En effet, pour écrire un poème, il faut satisfaire à deux contraintes en même temps : les vers doivent rimer et ils doivent avoir un sens. Il y a deux façons d’ imaginer comment un modèle y parvient :
l’ improvisation pure – le modèle pourrait écrire le début de chaque ligne sans se soucier de la nécessité de rimer à la fin. Puis, au dernier mot de chaque ligne, il choisirait un mot qui (1) a un sens compte tenu de la ligne qu’il vient d’écrire et (2) correspond au schéma de rimes;
la planification – le modèle peut également adopter une stratégie plus sophistiquée. Au début de chaque ligne, il pourrait imaginer le mot qu’ il prévoit d’ utiliser à la fin, en tenant compte du schéma de rimes et du contenu des lignes précédentes. Il pourrait ensuite utiliser ce « mot prévu » pour rédiger la ligne suivante, de manière à ce que le mot prévu s’ insère naturellement à la fin de la ligne.
Lequel des deux modèles est correct ? Vu l’ algorithme des modèles de langage, on pourrait pencher pour la première hypothèse. C’ était d’ ailleurs ce que pensaient des chercheurs au début de leurs recherches. Et pourtant, ils ont trouvé des éléments suggérant clairement que le modèle fait de la planification plusieurs mots à l’ avance…
Comme on peut le voir sur la figure 6, le modèle planifie à l’ avance plusieurs possibilités pour le mot final de la ligne, et planifie ensuite le reste de la ligne « à l’envers » pour que cette dernière soit cohérente.
Figure 6 : Planification direct et inverse d’ une rime (source: Anthropic)
Les chercheurs ont également modifié les concepts en cours d’ élaboration de la rime. Le modèle prévoyait de terminer sa ligne par « rabbit » mais si l’ on annule ce concept en cours de route voire le remplace par un autre, le modèle change de rime.
Figure 7 : Modification du concept final en cours de rime (source: Anthropic)
Ceci montre que les modèles préparent leurs réponses plusieurs mots à l’ avance, et sont non seulement capbles de planifier vers l’ avant mais aussi vers l’ arrière (rétro-planning) quand c’ est nécessaire. Les modèles sont aussi capables de planifications multiples en parallèle, et il est possible d’ intervenir directement sur ces plans en cours de route en modifiant les concepts sous-jacents.
Conclusion
Ces recherches lèvent un coin du voile sur ce qui se passe réellement au sein des modèles de langage. Il me semble clair que ces recherches ne sont qu’ à leurs débuts et que beaucoup de choses sont encore à découvrir dans le domaine de l’ interprétabilité.
Si vous voulez en savoir plus sur ce sujet, je ne puis que vous suggérer de lire directement l’ article On the Biology of a Large Language Model que je cite ci-dessous en référence. Les chercheurs y présentent douze traces de raisonnement différentes apportant chacune son lot d’ enseignements…
Pour ma part, ce qui me fascine le plus, ce sont les analogies évidentes entre la manière dont ces modèles « réfléchissent » et la manière dont nous le faisons…
Et voilà, j’ ai décidé de joindre le geste à la parole dans le cadre de la résilience digitale. J’ ai transféré le nom de domaine et l’ hébergement du blog vers l’ Union Européenne. Le blog se trouve maintenant à l’ adresse https://artificiellementintelligent.eu qui est hébergé par la société française OVH, un des leaders européens dans le domaine et offre des hébergements WordPress compétitifs. L’ancien site reste provisoirement accessible sur https://artificiellementintelligent.wordpress.com.
Ce message est donc le premier que vous recevez depuis la nouvelle mouture du blog, ce qui explique aussi la modification du format des emails de notification car j’ai dû adapter la configuration et les plug-ins de WordPress chemin faisant.
Ces préliminaires étant dits, je vais faire un rapide point sur la situation actuelle des modèles de langage. Les modèles de langage actuels peuvent grosso modo se regrouper en trois grandes catégories :
les modèles généralistes : ces modèles sont focalisés sur la conversation et le dialogue. Ils puisent dans leurs vastes connaissances, recherchent des informations et répondent de manière interactive aux questions variées de l’ utilisateur. Souvent multimodaux, ils peuvent aussi interpréter des images, de l’ audio voire de la vidéo et sont parfois capables de générer nativement des images. Ils sont habituellement accessibles via des interfaces web ou des applications mobiles conversationnelles;
les modèles de codage : ces modèles excellent dans l’ analyse et la génération de programmes informatiques. Ils sont typiquement exploités via des environnements de développement comme VSCode qui utilisent l’ interface de programmation pour accéder au modèle. Ces modèles sont en général capables d’ interpréter les images (diagrammes, interface utilisateur…) et se caractérisent par des fenêtres de contexte de grande taille, vu la taille souvent importante des codes source;
les modèles raisonneurs : ces modèles sont entraînés à construire des chaînes de raisonnement logiques. Ils sont à la base des applications comme « Deep Research » qui permettent d’ analyser un sujet de manière approfondie et de rédiger un rapport détaillé. La tendance actuelle est de leur adjoindre différents outils accessibles en cours de raisonnement afin qu’ ils puissent tester leurs hypothèses et continuer à raisonner sur les résultats intermédiaires obtenus. C’ est la voie vers les fameux « agents » dont on entend beaucoup parler et qui devraient enregistrer des progrès importants cette année.
Sur base de cette classification simple, voici les modèles « phare » actuellement mis à disposition par les principaux acteurs :
Modèle généralistemultimodal
Modèle de codage
Modèle raisonneur
OpenAI
ChatGPT-4o
GPT-4.1
o3
Google
Gemini 2.5 Pro
Gemini 2.5 Pro
Gemini 2.5 Pro Deep Think
Anthropic
Claude 3.7 Sonnet
Claude 3.7 Sonnet
Claude 3.7 Sonnet Extended Thinking mode
Meta
Llama 4 Maverick
Code Llama 4 (pas encore disponible)
Llama 4 Behemoth (pas encore disponible)
Mistral
Pixtral Large
Codestral
Mistral Large
Figure 1 : Modèles « Haut de gamme » des principaux acteurs, par type d’ utilisation
Il est aussi intéressant de connaître les modalités supportées par les modèles généralistes :
Modalités d’ entrée
Modalités de sortie
ChatGPT-4o
texte, audio, images, vidéo
texte, audio, images
Gemini 2.5 Pro
texte, audio, images, vidéo
texte
Claude 3.7 Sonnet
texte, images
texte
Llama 4 Maverick
texte, images, vidéo(?)
texte
Pixtral Large
texte, images
texte
Figure 2 : Modalités natives des modèles généralistes
OpenAI offre une palette différenciée de modèles; l’ objectif est de combiner l’ ensemble des capacités en un modèle unique à l’ architecture entièrement nouvelle (le fameux GPT-5), probablement vers la fin de l’ année 2025. Le modèle ChatGPT-4o présente la plus modalité la plus riche de tous les modèles du marché : il est capable d’ analyser, texte, image, audio et même vidéo et de générer nativement du texte et des images !
Notons qu’ OpenAI a décidé de retirer son modèle ChatGPT-4.5, trop coûteux à l’ exploitation pour se focaliser sur ChatGPT-4o pour les interactions conversationnelles et GPT-4.1 pour le codage.
Google est très bien placé avec Gemini 2.5 Pro qui intègre l’ ensemble des capacités dans un seul modèle : conversation, multimodalité (certes moins complète que ChatGPT-4o), génération et exécution de code et raisonnement. Il me semble que Google, qui a longtemps joué en seconde voire en troisième position, semble bien positionné pour reprendre la tête du peloton.
Les modèles d’ Anthropic sont très réputés pour leurs excellentes performances en codage. Anthropic cherche maintenant à renforcer sa position sur ce créneau en se concentrant sur leschaînes de raisonnement complexes avec appel d’ outils intégrés, y compris les environnements d’ exécution de programmes. Leur protocole standardisé MCP (Model Context Protocol), qui permet à un modèle de langage d’accéder à différents outils, s’ inscrit dans cette optique. Par contre, Anthropic accorde moins d’ importance à la multimodalité -moins utile pour la programmation- et leurs modèles ne peuvent générer que du texte et du code.
Enfin, Meta se caractérise par la disponibilité de leurs modèles en format open-weights, ce qui veut dire qu’ils sont utilisables localement. Ceci offre de grands avantages en termes de sécurité et de confidentialité à condition de disposer de machines suffisamment puissantes pour exécuter les modèles. Meta n’ offre pas encore de modèle raisonneur, ce dernier (appelé Behemoth) devrait cependant bientôt être annoncé.
Tous les modèles mentionnés sont de très bon niveau. Pour le travailleur intellectuel « col blanc » typique, la meilleure chose à faire est d’ essayer rapidement les différents modèles pour choisir celui qui vous convient le mieux, et ensuite de vous y tenir et de l’ utiliser chaque fois que vous vous posez une question ou recherchez des informations. C’ est comme cela que vous comprendrez progressivement comment intégrer ces modèles dans votre vie quotidienne et en tirer le meilleur parti.
Le monde de l’ IA générative est en ébullition suite à la publication du modèle R1 par la société chinoise DeepSeek la semaine passée.
DeepSeek-R1 est un modèle de raisonnement open-source innovant: contrairement aux modèles de langage traditionnels qui se concentrent sur la génération et la compréhension de textes, DeepSeek-R1 se spécialise dans l’ inférence logique, la résolution de problèmes mathématiques et la planification. Il se positionne dès lors comme un concurrent direct d’ OpenAI-o1 dont j’ai parlé dans mon article précédent.
DeepSeek est une entreprise d’IA chinoise fondée en 2023 par Lian Wenfeng et basée à Hangzhou, près de Shanghaï. Elle se consacre au développement de l’ Intelligence Artificielle Générale. La société DeepSeek compterait environ 200 personnes et est financée par le fonds d’investissement High-Flyer également fondé par Lian Wenfeng.
Le modèle R1 est extrêmement intéressant à plusieurs titres.
Tout d’ abord, il s’ agit d’ un modèle « raisonneur » au même titre qu’ OpenAI-o1 et ses performances sont comparables. Mais à la différence d’ o1, ce modèle est open-source et peut être librement téléchargé et exécuté localement. Qui plus est, DeepSeek a décrit en détail le mécanisme d’ apprentissage par renforcement utilisé pour passer de leur modèle de langage « standard » DeepSeek-V3 au modèle « raisonneur » DeepSeek-R1 (un lien vers le document technique est fourni en référence).
Ensuite, le modèle aurait été développé avec un budget assez limité – on parle de 6 millions d’ USD- ce qui est peu comparé aux dépenses de ses concurrents américains.
Les performances du modèle DeepSeek-R1 étant plus qu’ honorables, cela signifie qu’ une grande partie de l’ avantage compétitif de sociétés « fermées » comme OpenAI a disparu et se retrouve accessible à tous.
Il s’ agit donc d’ un fameux coup de pied dans la fourmilière qui va sérieusement ouvrir le jeu et permettre de nouvelles innovations.
Accéder au modèle
Le modèle DeepSeek-R1 est exploitable de trois manières différentes :
Tout d’ abord, vous pouvez dès aujourd’hui tester DeepSeek-R1 via l’ interface web accessible ici après inscription. Cet accès est entièrement gratuit.
Figure 1 : L’interface utilisateur DeepSeek
L’ interface est très simple et propre. Vous devez cliquer sur le bouton DeepThink (R1) pour utiliser DeepSeek-R1, sinon c’ est le modèle DeepSeek-V3 qui vous répondra.
Seconde possibilité, vous pouvez utiliser le modèle via l’ Interface de programmation (API) de DeepSeek qui est compatible avec celle d’ OpenAI. Les mécanismes d’ accès sont décrits ici.
Le point-clé ici est le prix extrêmement bas pratiqué par DeepSeek par rapport à OpenAI. Le tableau ci-dessous compare les prix entre OpenAI et DeepSeek :
Figure 2 : Comparaison des prix d’ accès via l’ API
Une remarque cependant : DeepSeek se réserverait la possibilité de réutiliser vos interactions avec le modèle pour des entraînements ultérieurs; évitez donc de transmettre des données confidentielles ou personnelles dans vos interactions, que ce soit via l’ interface Web ou via l’ API.
Troisième possibilité, comme le modèle est open-source, vous pouvez télécharger ses paramètres et l’ exécuter localement. Le modèle R1 complet contient cependant 670 milliards de paramètres ce qui le met hors de portée de la plupart des ordinateurs….
Pour contourner cela, DeepSeek met à disposition des « distillations » de son modèle qui sont, elles, de taille beaucoup plus accessible : elles vont de 1,5 à 70 milliards de paramètres. Des programmes comme Ollama ou LMStudio proposent dès aujourd’ hui ces modèles pour téléchargement et exécution locales.
Figure 3 : Liste et performances des versions distillées de DeepSeek R1 (source : DeepSeek)
Le processus de distillation consiste à partir d’ un autre modèle open-source (Qwen, LLama…) et à l’ affiner sur des traces de raisonnement générées par DeepSeek R1. On obtient en sortie un modèle certes moins performant que R1 mais meilleur en raisonnement que le modèle de base dont il est dérivé. Le modèle qui en résulte est donc une sorte de compromis…
Performances
Le modèle DeepSeek présente des performance comparables à celles d’ OpenAI-o1 lorsque les deux modèles sont évalués à travers six benchmarks couramment utilisés pour évaluer les modèles de langage, à savoir :
AIME2024 et MATH-500 sont deux tests destinés à évaluer les capacités de raisonnement mathématique des LLM;
CodeForces et SWE-Bench Verified sont deux tests de la capacité à programmer et résoudre des problèmes informatiques réalistes;
GPQA Diamond est une liste de 198 questions très difficiles en sciences naturelles : biologie, physique et chimie;
MMLU est un test plus large qui couvre non seulement les sciences exactes mais également les sciences humaines et sociales.
Le graphique ci-dessous présente les résultats d’ évaluation :
On voit en effet que DeepSeek-R1 tient la dragée haute à OpenAI-o1 sur chacun des six tests.
Il est aussi intéressant de constater que le modèle distillé DeepSeek-R1-32B (distillé à partir de Qwen-32B) présente des résultats tout à fait honorables et assez proches de ceux d’ o1-mini; or un tel modèle est tout à fait exécutable localement sur une machine de performances convenables.
Enfin, on voit bien l’ impact de l’ apprentissage par renforcement si l’ on compare les performances de DeepSeek-R1 avec celles de DeepSeek-V3 puisque R1 n’est autre que V3 ayant subi un entraînement complémentaire par renforcement.
Censure ?
L’ utilisation des modèles de DeepSeek a fait apparaître un point assez surprenant : le modèle refuse de parler de sujets tabous en Chine comme la souverainté de Taiwan, la disparition de l’ ancien Ministre des Affaires Etrangères Qin Gang, la famine causée par le Grand Bond en Avant de Mao Tsé-Toung ou encore le massacre de la place Tien An Men en 1989.
Ce qui est assez étonnant, c’est que le modèle commence par rédiger tout un texte puis ce dernier disparaît soudain pour présenter ceci :
Figure 5 : Aspects de censure
Cela donne vraiment l’ impression qu’ un robot censeur intervient en fin de génération pour valider ou rejeter le texte. En tous cas c’ est la première fois que je vois un modèle de langage faire cela…
Conclusions
Il est fort probable que l’ arrivée de DeepSeek-R1 va ouvrir grand les vannes des modèles « raisonneurs ». non seulement les algorithmes sont maintenant publiés au grand jour mais DeepSeek autorise quiconque à utiliser les générations de DeepSeek-R1 pour entraîner -ou plutôt distiller- d’ autres modèles afin de les améliorer.
Malgré les réserves relatives à la censure et la réutilisation des données, il faut saluer le tour de force réalisé par l’ équipe de DeepSeek qui a réussi à développer un modèle open source pour environ 5 millions de dollars et dont le coût d’ exploitation est trente fois inférieur par token comparé à OpenAI, qui reste un système fermé.
Cela pourrait remettre en question les milliards de dollars investis par OpenAI pour conserver son avantage technologique, et cela juste au moment où ils annoncent un investissement titanesque (500 milliards) dans le projet Stargate…l’ année 2025 commence fort.
Malheureusement, l’ Europe semble bien absente de cette accélération. Espérons que l’ annonce du Plan de Compétitivité de l’ Union Européenne la semaine prochaine permette de libérer nos forces créatrices. Il est grand temps.