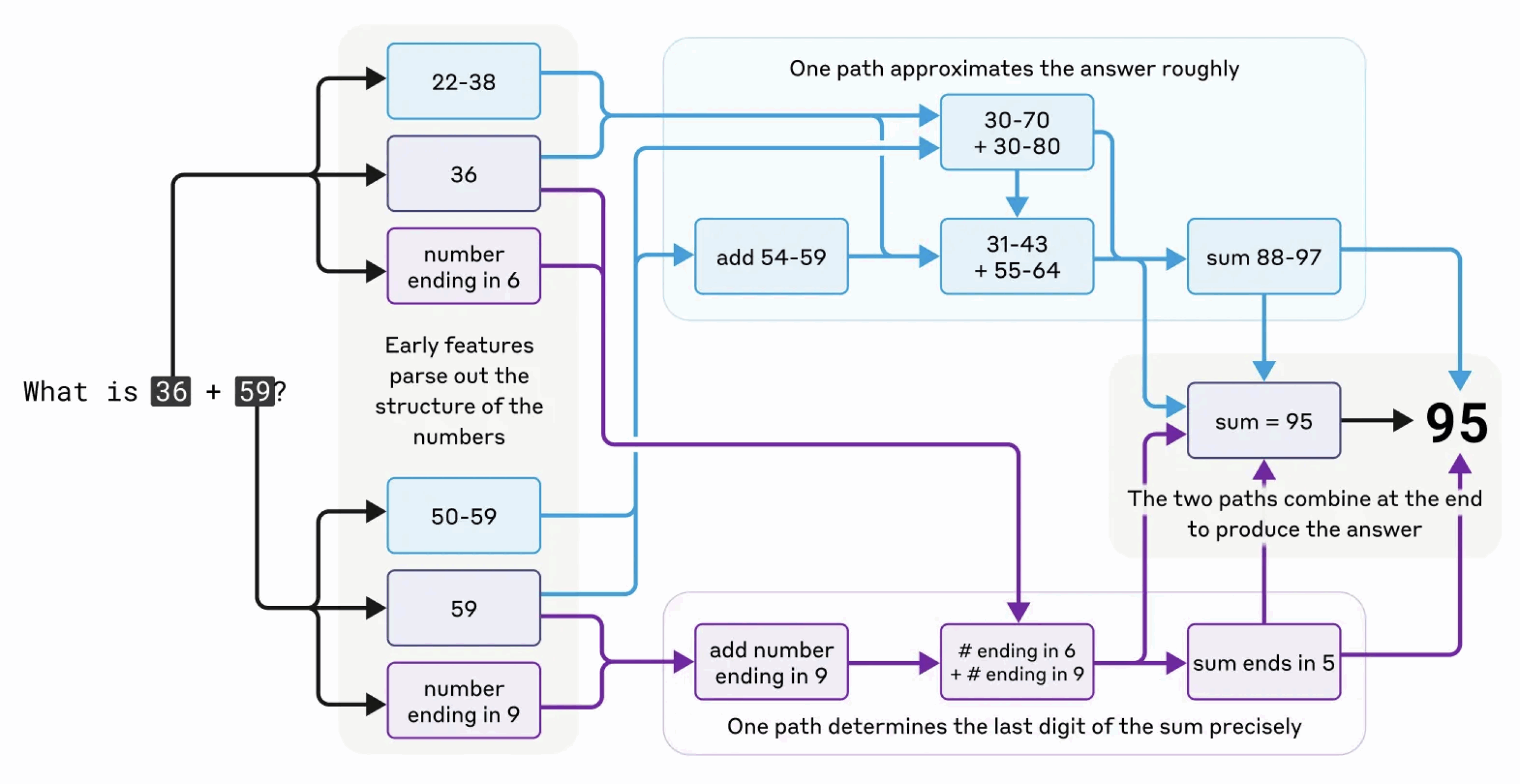
Le mode d’ utilisation des modèles de langage est en pleine mutation. Nous passons de la période des « chatbots » en ligne à celle des agents IA. Ils excellent déjà dans le domaine de la programmation: j’ ai passé les dernières semaines à utiliser Claude Code pour un projet d’ application en ligne.
Claude Code est plutôt orienté programmation, mais Anthropic a déjà mis en ligne un équivalent pour les tâches bureautiques appelé Claude Cowork. Même si vous ne programmez pas, je vous suggère d’ essayer au minimum Cowork, parce que cela va avoir des impacts sur le monde professionnel.
1. Qu’ est-ce qu’ un agent IA ?
Ce qui rend Claude Code et Claude Cowork si puissants repose sur une idée assez simple : une boucle qui va lire des fichiers et exécuter vos commandes sur ces fichiers de manière répétitive jusqu’ au moment où vous décidez d’ arrêter la session. Votre but premier est de pousser l’ agent à transformer les fichiers se trouvant dans le répertoire jusqu’au résulat désiré : présentation, rapport ou programme applicatif…
Quel est l’ avantage par rapport à une interface web classique type ChatGPT ? Dans une interface conversationnelle classique, vous devez jouer le rôle de la « petite main » qui va sans cesse copier-coller les fichiers source, recopier et exécuter les commandes et fournir en retour au modèle les messages d’ erreur, fournir du contexte en chargeant manuellement des fichiers de support etc…
Tout cela est fini. L’ agent s’ occupe de modifier directement les fichiers. Mais il y a plus : l’ agent peut aussi exécuter directement des commandes et en voir le résultat, puis les répéter automatiquement jusqu’ à obtenir le résultat attendu. Vous pourriez lui dire : « corrige le bug dans auth.py » et le laisser se débrouiller pendant que vous allez prendre un café. L’ agent lit le fichier, l’ analyse et décide éventellement de lire d’ autres fichiers pertinents; il identifie ensuite et corrige le problème dans le fichier, lance des tests, analyse le résultat et recommence en cas d’ échec, jusqu’à finalement aboutir (ou abandonner)…
Bref, une agent IA est une application informatique qui va :
- attendre une consigne de l’utilisateur
- consulter un modèle de langage pour évaluer les actions à prendre
- exécuter les actions (lire/changer des fichiers, exécuter des commandes, exploiter des API…)
- observer le résultat des actions
- décider quelle action entreprendre ensuite
- répéter jusqu’ à obtenir le résultat désiré ou abandonner
- rendre la main à l’ utilisateur en expliquant ce qui s’ est passé
2. Comment « bien » utiliser ces agents ?
Commençons par deux règles de bonne pratique :
- Pour les tâches complexes, demandez à l’ agent de constituer un plan d’ action avant de démarrer l’ exécution. La planification est un mode de fonctionnement spécifique que vous pouvez activer. Une fois le plan généré, relisez-le et demandez à l’ agent de le modifier jusqu’à obtenir satisfaction. Ne lancez l’ exécution que quand le plan vous convient.
- Dans la mesure du possible, essayez d’ avoir un mécanisme d’ évaluation du résultat en place, afin que l’ agent puisse valider sont travail ou l’ adapter si nécessaire. Fermer la boucle rend l’ agent beaucoup plus autonome. Etablir des tests automatisés est souvent possible pour du code informatique, mais pas toujours évident pour d’ autres tâches cognitives.
Dans tous les cas, il est préférable d’ avoir bien décrit la requête et le contexte au préalable dans un document que vous pourrez réutiliser au besoin. Ce que vous tapez dans la conversation ne survivra pas à la session en cours, tandis que ce que vous écrivez dans un fichier restera toujours exploitable.
Autre suggestion, privilégier les fichiers « texte » qui contiennent peu ou pas de formatage. Le code informatique répond parfaitement à cette exigence. Et pour les applications bureautiques, mieux vaut un fichier au format Markdown qu’ un fichier Word/Excel/pdf, car c’ est le format le plus efficace en terme de consommation de tokens.
3. Sécurité et permissions
Donner à l’ agent un accès direct aux système de fichiers et à la ligne de commande constitue un risque de sécurité évident. C’est pourquoi les agents IA possèdent un modèle de permissions assez sophistiqué que vous pouvez adapter en fonction des besoins.
Pour les actions pouvant impacter le système, la permission par défaut est en général « Ask », qui signifie que l’ agent va demander votre autorisation au cas par cas. Pour les actions en lecture seul, la permission est en général « Allow » au moins pour le répertoire de travai. Des commandes plus agressives seront bloquées par défaut (« Deny »).
4. Etendre le modèle IA avec les plug-ins
Un agent IA qui se respecte aura peut-être besoin de faire plus que manipuler des fichiers locaux pour atteindre le résultat attendu. Recherches sur le web, consultation d’ une base de données, consulter un catalogue de produits, voire même placer une commande sur Amazon : tout cela est possible via un mécanisme astucieux appelé « plug-ins » permettant d’ étendre les capacités de Claude Code et Claude Cowork en fonction des besoins.
Ce mécanisme de « plug-ins », développé par Anthropic, repose sur deux idées : les skills, qui sont une description textuelle de compétences additionnelles que l’ on veut attribuer à l’ agent (par exemple : spécialiste en cybersécurité) et les serveurs MCP qui décrivent comment accéder à des services tiers via une interface de programmation. Les deux concepts se renforcent mutuellement au sein du même plus-in : un skill va expliquer comment l’ agent peut exploiter un serveur externe dont l’ accès est fourni par le serveur MCP.
Ces plus-ins sont disponibles sur des sites appelés Marketplaces. Le système est donc assez simple à utiliser : définissez la Marketplace que vous voulez utiliser dans l’ agent IA et ensuite, parcourez la liste des plug-ins et installez ceux qui vous intéressent. Et voilà, votre agent est dispose maintenant de capacités étendues…
5. Conclusions
Le mécanisme d’ agents IA mis en avant par Claude Code et Claude Cowork qui offrent un moyen de multiplier la valeur ajoutée d’ un modèle de langage à travers un environnement d’ exécution interactif offre de larges perspecives et va impacter de nombreux domaines cognitifs.
Une fois que les mécanismes d’ extension des compétences et d’ interfaçage seront tout à fait matures (ce qui n’ est pas encore le cas), ces agents pourront coordonner des opérations complexes. Le chemin parcouru est impressionnant quand on pense que ChatGPT 3.5 a été publié en novembre 2022 soit il y a à peine trois ans.
Néanmoins, ces modèles ne fonctionnent que si les instructions qu’ils reçoivent sont suffisamment claires, et même dans ce cas, il subsiste toujours un risque d’ erreur. Les tâches de nature « systématique » sont mieux servies par un algorithme clasique que par un agent brillant mais incertain. Quitte à utiliser le génie en silicium pour écrire le programme…
Sources et références
- Tweet X de Eyad : The Complete Claude Code tutorial : https://x.com/eyad_khrais/status/2010076957938188661?s=20
- Tweet X de Eyad : The Claude Code tutorial level 2 : https://x.com/eyad_khrais/status/2010810802023141688?s=20
- Tweet X de Nader Dabit : You could’ve invented Claude Code : https://x.com/dabit3/status/2009668398691582315?s=20
- Article X de Numan Ali : Claude code’s new task system, the practical guide and explainer : https://x.com/nummanali/status/2014684862985175205?s=20